
AI has moved into a more open-source era — from datasets to tools, it has become easier than ever to incorporate more “off-the-shelf” tools into your own work. Foundation models like Meta’s SAM (Segment Anything Model) make it easier than ever before to perform tasks like segmenting objects. Trained on 11 million images and at least one billion masks, Meta has positioned SAM as a way to effectively “cut out” objects with just a few simple clicks.
But is a general model like SAM good for everything? ML systems have enormous potential to change how we work, but as any engineer knows, it’s the edge cases that most often cause failures. How does SAM respond to specific annotation needs for a dataset? At Sama, we set out to test not just this, but specific limitations caused by SAM’s generalized focus. After all, we have found that manual editing of ML-generated annotations can actually take longer than creating those annotations from scratch as a human, meaning that the time savings of SAM—which can produce a segmentation in 50 milliseconds—may be lost.
In particular, three potential limitations were observed, all revolving around specific or fine details. First, very fine detail can be lost in the image encoding process, due to SAM’s use of a standard Transformer architecture resulting in lower-resolution embedding. This loss of finer detail and other specificity in datasets may also result in the inability to correctly segment or identify characteristics when required by the dataset (for example, whether or not an object has holes). Finally, without refinement or zoom-in functionalities, SAM cannot account for these issues at other points in the process.
Using the COCO dataset, we tested the following models, based on SAM’s own recommendations for segmentation approaches:
- Our custom model, which uses point clicks to the top, bottom, left-most, and right-most parts of the target object as input
- A “SAM loose box” model, which uses SAM’s bounding box approach with a 20% buffer to the box sidelength; the buffer value was determined based on our experience in the industry
- A “SAM tight box” model, which required exact bounding boxes
After using these models and the COCO dataset, we then calculated the mean Intersection over Union (mIOU) score to reflect how accurate each model was in segmenting objects compared to the ground truth of the data. The results are reflected below, separated out by different categories:
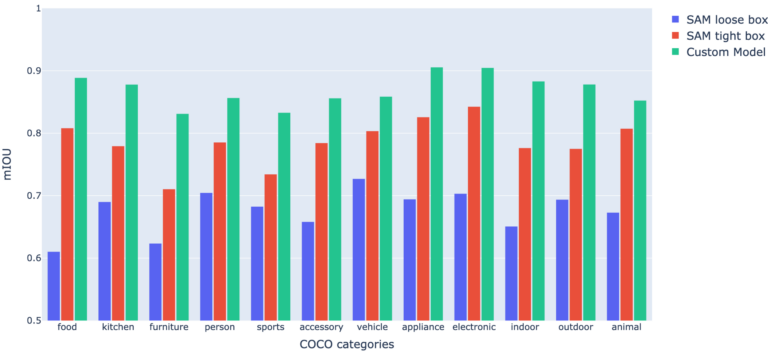
Generally, an IOU or mIOU over 0.7 can be considered good, while a score over 0.9 is excellent. As you can see, the SAM loose box model had the weakest performance of all three models, often significantly weaker than even the SAM tight box model (in particular with food, accessories, and indoor categories). The SAM tight box model, in comparison, scored at the “good” benchmark of 0.7 or better in all categories tested, and the Sama model was able to exceed 0.9 in two categories while approaching it in several others.
To further compare the three models, we took an additional 10K images with 56K segmented objects for testing from a customer dataset, focusing on the automotive category in urban settings. After training each model on 40K images containing 220K segmented objects, we then set the following parameters:
- Segment instances into two categories: pedestrians and vehicles
- Group multiple overlapping objects of the same category into a single object
- Include holes as part of the foreground
Here, the SAM loose box and tight box models both struggled with the pedestrian category in particular.
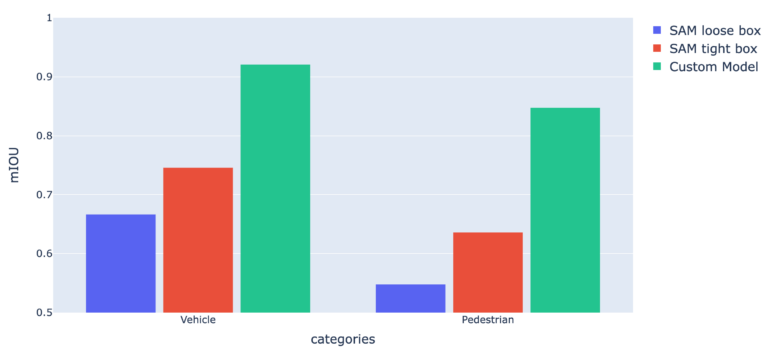
With these data points in hand, the conclusions are fairly clear. Foundation models have the potential to be extremely useful in saving time during segmentation and other processes — and are already producing impressive results given their general lack of training on specific datasets. However, for specific and narrow problems, a small and customized model still outperforms large and uncustomized models.
Further advancing user interaction capabilities may be a key to unlocking better performance from foundational models. SAM, for example, has other interaction capabilities; the tests conducted only focused on bounding boxes. Making it easier to use foundational models will make them easier to incorporate across different projects and save time.
Furthermore, incorporating the ability to handle dataset-specific policies could significantly increase SAM’s mIOU score relative to these tests. While SAM is a great out-of-the-box tool, the ability to fine tune policies may end up being critical for applications where accuracy is essential.
We are still in the early stages of the use of foundational models overall. With that in mind, SAM is already an impressive tool, and further refining it and other models could help us rethink how we perform annotation at scale.
