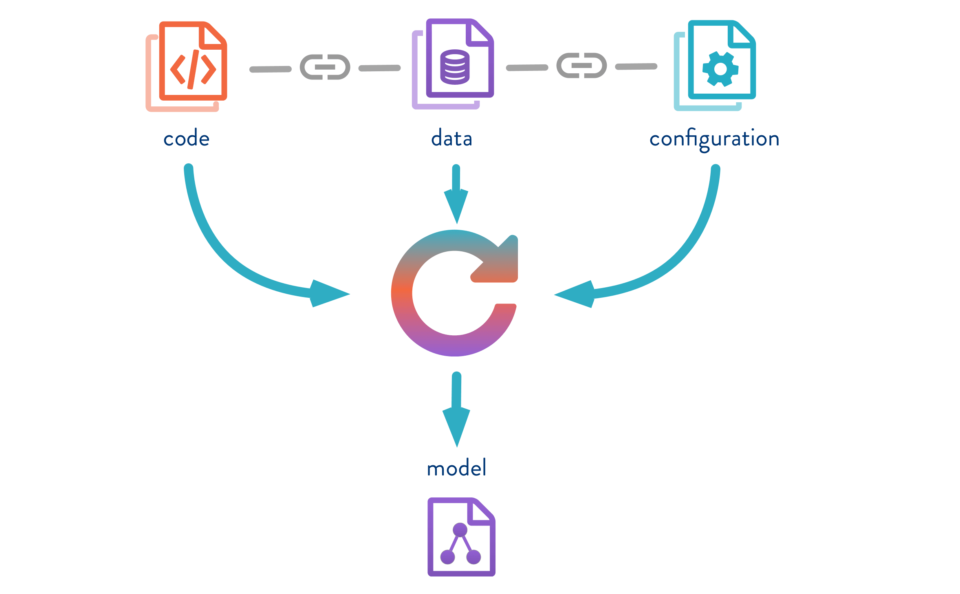
Data Version Control (DVC) is a way of controlling and maintaining the content of a website. Instead of having separate files in every development branch, it is used to control all the content. Git, for example, is an example of a DVC tool. Git allows users to push local code to a remote repository. This gives developers a single source of truth while still allowing local work to happen. A DVC data repository is essentially a folder on a computer or network.
Data versioning
Data versioning and version control is essential in scientific research, as errors can have significant consequences when data is used to make decisions. One recent example of this problem was the retraction of a study on COVID-19, a cancer drug, in response to insufficient reproducibility. This prompted another study to retract its results using the same dataset. The lack of best practices in data versioning has been identified as a contributing factor to this problem.
To address this problem, data publishers and providers must publish data versioning policies and procedures. The process must be rigorous and documented to enable proper attribution and credit to be given for their data products. In addition, data publishers and providers must create machine-readable records of any changes made to data. The purpose of data versioning and version control is to provide a means of monitoring changes in data products.
Another application for data versioning and version control is machine learning. When a machine learns to recognize different types of data based on a large number of samples of the same type, it can improve its performance. Data versioning is crucial for image recognition systems, as code updates are necessary to teach the machine learning algorithm new techniques.
Data versioning and version control can improve workflow and minimize errors, it enables repeatability and traceability. The process can be automated by using data versioning tools.
Git
Git for data version control is a new project that brings the benefits of Git to data projects. It is designed to be user-friendly and suitable for small character separated files. It has several benefits over other data version control tools. In particular, it can keep track of changes and can easily identify errors and feature requests.
Git uses files and snapshots to keep track of changes. It also links to previous versions. The files and folders it manages are saved using a checksum so that any changes made can be tracked. Git can be used on local computers, as it does not require access to a server.
Git makes it easy to manage data by providing a way to create, store, and switch between different versions. This makes it easy to create a single history of data and journal of work. It can also be used in the cloud for data storage. Its benefits include making it easier for you to collaborate with others.
Reverting single revisions can cause conflicts. The revert action is not automatic in Git. You need to manually do it by using the command line. Once you’ve completed this step, you can change the update strategy later by changing the settings in the Settings dialog.
Time to live policy
A Time to Live (TTL) policy allows you to delete changes made to a data set after a specified amount of time. However, your versioning system may not support TTLs. If it does not, you can use a version clean-up script to achieve the same effect.
Data version control is essential to data-driven projects. It enables faster feedback cycles, which can happen several times a day in a traditional development project. This allows teams to run experiments more effectively and efficiently, and improves the quality of delivered results. It also helps improve collaboration between different teams.
Shared cache
Shared cache and data version control (DVC) are two software tools that allow you to manage data on a large shared volume efficiently. They both use Git for version control, and Git provides the ability to synchronize workspace data to.dvc files. This feature allows you to create a shared cache for a given project, and it can be used for training ML models. The shared cache can be created on a NAS drive or storage server mounted on a network. In this case, you will need to set up permissions and ownership of the directory to prevent any conflicts.
Data version control also enables you to keep a backup of all data in a shared cache, and it will prevent cache copies from being overwritten by the changed data. Cache copies can also be used for intertask temporal locality. This allows you to perform a number of tasks at the same time.
The key to shared cache and data version control is to maintain cache coherence, and to exploit the temporal locality of shared data across synchronization boundaries. In a shared cache, this approach doesn’t involve interprocessor communication, which keeps hardware requirements flat as the number of processors increases. Furthermore, this scheme incurs very little overhead.
The version control scheme involves three tasks: maintaining the CVNs, tagging the cache copy with a bvn, and performing runtime comparisons. These tasks can be done in parallel, without adding any hardware or software extensions.
Pipelines
Pipelines for data version control help teams work more efficiently and deliver quality results faster than ever before. With the right tool, they can execute experiments faster and improve models more effectively. In addition, these data versioning tools help teams work together on the same code. These features can improve collaboration, improve speed, and reduce development costs.
Data scientists work with large amounts of data and metrics, which require the proper organization. These varying versions of data need to be tracked and managed in order to be analyzed and used for machine learning. Pipelines for data version control can help teams manage the various data sources and ensure reproducibility in machine learning experiments.
Many data analysts work with many different datasets, including external and internal data. Managing them manually can be error-prone and time-consuming. With pipelines for data version control, data engineers can have a single interface for collaboration and data versioning. Data engineers and scientists can also access different versions of the same data easily and efficiently.
Pachyderm is a version control tool for machine learning projects. It allows machine learning teams to easily control the entire machine learning life cycle. It offers three different versions: open-source, beta, and hosted. The open-source version of the tool is a great choice for agile collaboration.
.gitignore
Using.gitignore for data version control is a good idea if you regularly make changes to your code and want to avoid losing old versions. There are two main ways to use this file. First, you can specify specific files and folders in the repository itself. Secondly, you can specify specific files or folders in the distributed version of the repository.
Second, you can specify files you want to be excluded from Git. A.gitignore file contains a pattern list of files and directories that you don’t want to be included in the repository. The pattern file can be in the $GIT_DIR/info/exclude directory.
Third, you can set a global.gitignore file to exclude files that are not part of the repository. This will prevent you from accidentally uploading them to GitHub. Alternatively, you can add a file to your.gitignore for data version control that excludes the train/val/ folders.
The.git log contains useful information about commits. It contains information about the date and time the files were committed, the author of the commit, and the message that was sent with the commit. This log can help you track the history of your changes in the code. In addition, you can see what files were changed during a commit by using the git log command.
In addition to the local repository, you can also use a remote repository. The remote repository is another folder on your system. DataLad and DVC are examples of data version control solutions. Both of these solutions use a remote repository as their main repository.
